Tuesday, September 13, 2011

Tuesday, August 30, 2011
Choosing your database – SQL or NoSQL?
Lots of discussions are coming up lately on management of data in the traditional SQL-RDBMS way versus the emerging NoSQL way. As application designers, developers and architects, how do we choose which way to go? This is a common dilemma these days when the scale of applications as well as data volumes are ever increasing and processing terabytes of data have become common enough.
What exactly is the difference between SQL & NoSQL?
The major differences are in the data access patterns and data organization.
NoSQL databases allow a restricted predefined data access pattern. The basic philosophy here is that ultimately my application is the best judge to decide how to manipulate my data and I don’t want some blackbox like a query optimizer sitting inside my database to decide how my application should retrieve or manipulate my data. e.g HBase can be used more as a distributed persistent key value store where in my access pattern is well defined and very simple - I can look up based on a key and retrieve all/some values. So what I get is scalability and performance which are predictable. The price I have to pay is that I won’t get flexible arbitrary data access patterns with my favorite SQL queries. So it is a trade-off, I get more power and as always, power comes with a lot of responsibilities – you need to take care of a lot of things at the application level that your RDBMS would have silently done for you. NoSQL databases also give you the flexibility to store semi-structured or un-structured data and you are free to think beyond the conventional ‘tables’ with ‘rows’ and ‘columns’.
A few examples for NoSQL databases are HBase, Cassandra, Hypertable, CouchDB ,MongoDB etc
SQL databases need you to make some assumptions on your data access patterns based on which predefined optimizations like indexes are built. But if you ask me if we know exactly the data access pattern, I would say no.But definitely we have some idea about potential access patterns (e.g I would know which would be my primary key, foreign key etc.).The executions of queries are controlled by the database engine and programmers would have very limited control over it. So this is again a trade-off, I get simplicity, data normalization, data integrity and an ‘easy to work with’ language (SQL) but when it comes to scalability beyond a limit, it would be an issue. Another advantage I have is that it is very easy to comprehend a relational table since it is nothing but a simple structure with ‘rows’ and ‘columns’.
A few examples for SQL databases are Oracle, MySQL, PostgreSQL, Sybase etc
Ok now, why don’t you just tell me which one I should pick?
Just because Google, facebook, LinkedIn and other web companies do something doesn’t mean that you need to do the same. Just because there is too much buzz about something, it doesn’t mean that it would magically solve all your problems.
The key aspect is your problem. What you choose depends up on what problem you are trying to solve. Depending on your specific situation, SQL, NoSQL or even a hybrid solution supporting both might be appropriate .All I can say is that neither SQL or NoSQL are silver bullets. Sleep over your problems and choose wisely…Or ask others who have faced similar problems (it is very likely that problems we face are faced by someone else as well)-I have seen that this technique attest works
What exactly is the difference between SQL & NoSQL?
The major differences are in the data access patterns and data organization.
NoSQL databases allow a restricted predefined data access pattern. The basic philosophy here is that ultimately my application is the best judge to decide how to manipulate my data and I don’t want some blackbox like a query optimizer sitting inside my database to decide how my application should retrieve or manipulate my data. e.g HBase can be used more as a distributed persistent key value store where in my access pattern is well defined and very simple - I can look up based on a key and retrieve all/some values. So what I get is scalability and performance which are predictable. The price I have to pay is that I won’t get flexible arbitrary data access patterns with my favorite SQL queries. So it is a trade-off, I get more power and as always, power comes with a lot of responsibilities – you need to take care of a lot of things at the application level that your RDBMS would have silently done for you. NoSQL databases also give you the flexibility to store semi-structured or un-structured data and you are free to think beyond the conventional ‘tables’ with ‘rows’ and ‘columns’.
A few examples for NoSQL databases are HBase, Cassandra, Hypertable, CouchDB ,MongoDB etc
SQL databases need you to make some assumptions on your data access patterns based on which predefined optimizations like indexes are built. But if you ask me if we know exactly the data access pattern, I would say no.But definitely we have some idea about potential access patterns (e.g I would know which would be my primary key, foreign key etc.).The executions of queries are controlled by the database engine and programmers would have very limited control over it. So this is again a trade-off, I get simplicity, data normalization, data integrity and an ‘easy to work with’ language (SQL) but when it comes to scalability beyond a limit, it would be an issue. Another advantage I have is that it is very easy to comprehend a relational table since it is nothing but a simple structure with ‘rows’ and ‘columns’.
A few examples for SQL databases are Oracle, MySQL, PostgreSQL, Sybase etc
Ok now, why don’t you just tell me which one I should pick?
Just because Google, facebook, LinkedIn and other web companies do something doesn’t mean that you need to do the same. Just because there is too much buzz about something, it doesn’t mean that it would magically solve all your problems.
The key aspect is your problem. What you choose depends up on what problem you are trying to solve. Depending on your specific situation, SQL, NoSQL or even a hybrid solution supporting both might be appropriate .All I can say is that neither SQL or NoSQL are silver bullets. Sleep over your problems and choose wisely…Or ask others who have faced similar problems (it is very likely that problems we face are faced by someone else as well)-I have seen that this technique attest works
Tuesday, March 15, 2011
Harnessing Hadoop For Big Data Analytics

Harnessing hadoop for big data analytics v0.1
Posted the slides from the session on big data analytics using hadoop.The session was conducted at Travancore Hall,Technopark Trivandrum
http://www.thehindubusinessline.com/todays-paper/tp-others/tp-states/article1518273.ece
Posted the slides from the session on big data analytics using hadoop.The session was conducted at Travancore Hall,Technopark Trivandrum
http://www.thehindubusinessline.com/todays-paper/tp-others/tp-states/article1518273.ece
View more presentations from jobinwilson
Sunday, October 10, 2010
Workflow Solutions for Big Data Analytics - Can Oozie help?
A common pattern that we see in Big Data Analytics is that we are essentially operating on huge data pipelines which consume some input files (may be web logs/application logs etc) and do some heavy processing to generate insights that we store in an output file(s)/data store. Another data pipeline may consume this and generate even further insights.
The key points to note are
1.The data volume would be huge (would be in GBs/TBs)
2.We have many input sources from which this data will be arriving / needs to be extracted (push/pull)
3.We need to maintain some kind of a repository/warehouse which could be leveraged to consistently maintain the incoming data files, store intermediate/final results of our analytic processing
4.Analytics operations should be considered like "jobs" with an ETL nature
5.We would need some kind of an orchestration mechanism to manage the inter-dependencies of jobs & trigger jobs based on the availability of data, provide scheduling capabilities & recovery mechanisms etc.
Didn’t we discuss about these points in our last week's architectural meeting???-Well, these points sound familiar and we can easily look at it as a common challenge faced in a lot of big data analytics solutions.
Our Big Data solution stack may have hadoop, pig, hive ,custom map reduce jobs in java or we might use hadoop streaming etc..but the major problem still exists - Who will orchestrate my process flows which generates insights?
Wait...did you say process flow? Where did the "flow thingy" come from? I thought I could write a map-reduce program to do my analytics...Is that not the case? Well ,you can definitely write map-reduce programs, but an optimal way would be to leverage the higher level abstractions that already make your job easy in which ever stages you could use them. For instance I could use hive queries to quickly aggregate some data or use a pig script to do some input transformation .All these would get converted to map-reduce under the hood. Another reason why you can perceive it as a flow is because there will be a sequence of well defined steps that will take in data from a source, do some processing & feed it into a sink - A classic data pipe line.
You will see that lot of these steps will follow a common pattern and if we could have abstractions like “actions” which define each of this steps(what they do & which abstraction they use to complete the step) & link them as an sequence of steps, our job is done. A flow could be represented using xml and the abstractions for actions could be “pig action”, “file system action”, “map-reduce java action”, ”ssh action” etc
Looking from the above perspective, Yahoo’s Oozie (which is a workflow system for hadoop ) sounds promising.It has been around for almost a year and now there is a V2 version of it which has introduced a concept of “coordinator jobs” which exactly solves the scheduling & dependency management. The system is exposed via APIs and webservices & is deployed inside a tomcat.It provides an extjs based console also to monitor jobs.It also provides a command line based client.I saw a presentation on Oozie from hadoop summit 2010 & it seems to have addressed a lot of common pain points.
http://developer.yahoo.com/blogs/ydn/posts/2010/08/workflow_on_hadoop/
I have started playing with Oozie 2.2.0 this weekend .I will be posting the findings from my experiments soon. I did face some challenges in getting Oozie 2.2.0 installed on my hadoop cluster and in configuring mysql as the Oozie persistence mechanism. Since I couldn’t get a binary distribution from github, I started off by building a copy myself. Even after injecting extjs2.2 which it uses for rendering the console,I couldn’t get the Oozie web console working....Then firebug came to rescue, the problem was that RowExpander.js was being searched in the extjs home folder,but this script was located in the examples folder. I copied it over & repackaged oozie.war & it started working. I will be publishing a post with details on getting around the issues soon.
May be the issues are addressed in Oozie 2.2.2 & they have a distro available for download & we might not have to build it from source code.I am yet to try it out…
Tuesday, May 4, 2010
Adding HSQLDB Plugin to Eclipse
i wanted to play a little bit with HSQLDB and i thought it might be a good idea to add HSQLDB Plugin to my eclipse so that i can use it more seamlessly while i try out stuff in my java code from eclipse.The main advantage is that the footprint of the DB is so small and no complex installation is there.It doesn't consume much resources & is good enough while experimenting things in a dev box.
I thought of keeping some quick pointers here.
1.Download HSQLDB from sourceforge http://sourceforge.net/projects/hsqldb/
2.Download HSQLDBPlugin from sourceforge http://sourceforge.net/projects/hsqldb-plugin/files/
3.Unzip the HSQLDBPlugin zip,you will get two folders hsqldb.core and hsqldb.ui
4.Copy both the folders into ECLIPSE_HOME/plugins folder
5.Navigate to ECLIPSE_HOME/plugins/hsqldb.ui folder from command prompt/shell
6.run the command jar cvf ui.jar -C bin . (note the ending dot,denotes the current folder).This command will generate ui.jar
7.restart eclipse
Once we follow these steps,we will see a new link named "Add Database Engine Nature" appear in the right click menu of the eclipse project
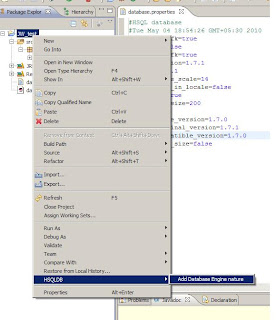
Clicking on this menu will then show up various options for starting/stopping/starting database manager etc
I thought of keeping some quick pointers here.
1.Download HSQLDB from sourceforge http://sourceforge.net/projects/hsqldb/
2.Download HSQLDBPlugin from sourceforge http://sourceforge.net/projects/hsqldb-plugin/files/
3.Unzip the HSQLDBPlugin zip,you will get two folders hsqldb.core and hsqldb.ui
4.Copy both the folders into ECLIPSE_HOME/plugins folder
5.Navigate to ECLIPSE_HOME/plugins/hsqldb.ui folder from command prompt/shell
6.run the command jar cvf ui.jar -C bin . (note the ending dot,denotes the current folder).This command will generate ui.jar
7.restart eclipse
Once we follow these steps,we will see a new link named "Add Database Engine Nature" appear in the right click menu of the eclipse project
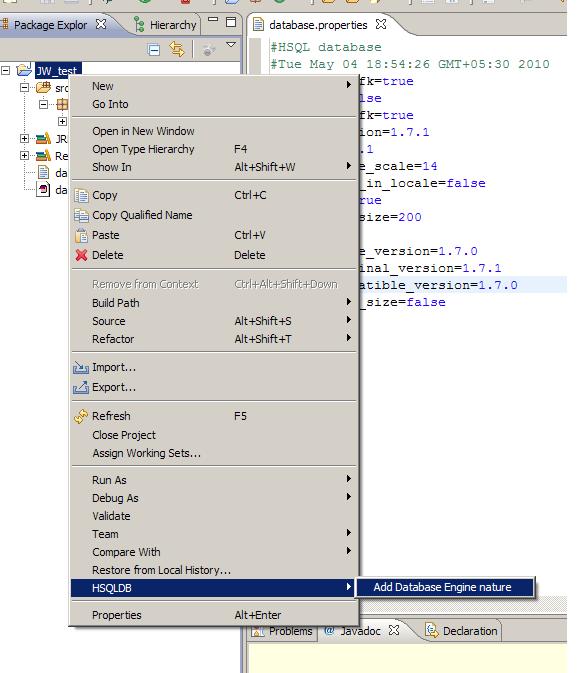
Clicking on this menu will then show up various options for starting/stopping/starting database manager etc
Sunday, January 31, 2010
Remedy:Open Window action (Dialog) displaying the form in a bigger size on a midtier
Sometimes you might have observed that in an activelink open window action(dialog) displays it as a bigger dialog on a browser.In the user tool the form is opened in the correct size (rendered based on the size of the components on the form).Even after removing the fields from view,the form-still gets scroll bars and a bigger sized window .Adding a few more fields below the form grows the form size is even bigger.Removing the newly added fields is also resulting in the same bigger sized form.
Solution:
Need to just do a small setting so that the form would be rendered in the required size on midtier as well.
In Developer studio,go to "Layout" menu and choose "Show Actual View Size" (short cut is CTRL+ALT+M) and adjust the view size as needed.
Save the form after your changes,flush the midtier cache
You should see the form in the appropriate size now
Solution:
Need to just do a small setting so that the form would be rendered in the required size on midtier as well.
In Developer studio,go to "Layout" menu and choose "Show Actual View Size" (short cut is CTRL+ALT+M) and adjust the view size as needed.
Save the form after your changes,flush the midtier cache
You should see the form in the appropriate size now
Sunday, October 25, 2009
10 Things I Wish I Knew About ITSM when i got started
When someone gets started with ITSM,there are a few points/concepts which if clear would make life much easy :-).There are couple of reasons for this -something which you think is a 'customization' that needs to be built,might be already existing in some form or the other or even there could be some existing functionality that would help you to build your customization very easily or even understanding them would help you to know in detail about how the product behaves
The points below were consolidated so that it can benefit everyone who works on BMC Remedy ITSM.
1.Multi-tenancy
In the BMC Remedy ITSM applications, the multi-tenancy feature is available for Data segregation based on company. Access to data is controlled by a user’s access to a company.
(reading up a little bit about field 112 would be helpful as-well).
This feature is enabled from Application Administration Console>Custom Configuration>Foundation>Advanced Options>System Configuration Settings-System Settings
2.Restricted and Unrestricted access
This is related to multi-tenancy & for restricting data access of individuals to only companies that are relevant for them.Unrestricted users can access data for all companies based on there application permissions (Say a Global Support Manager).This is configured from People form’s Login/Access Tab.Check “Unrestricted Access” for granting such an access to a user.For restricting access to specific companies, add them into “Access Restrictions” Table
3.ITSM in a DSO environment
ITSM Installer now provides more support for DSO (7.5.xx onwards).Another good thing about the installer is that it is consolidated (ServiceDesk,Change Management & Asset Management) & runs on multiple platforms (InstallAnywhere based).Enable user defined prefix from SYS:System Settings.The 'Custom prefixes' are one of the most important aspects of a DSO enabled environment for ITSM.Update SHR:SchemaNames in the other server for appropriate application prefix (user defined prefix).Update field default for field ID 1 to match the prefix setup in above step.For additional information,refer ITSM-DSO-Enablement.doc
4.ITSM plug-ins
Another common query is regarding the plugins used by ITSM.Below is a list of few important ones
4.1ARDBC Plugin : Provides Overview console functionality, a view of work assigned across multiple applications. Query on the Vendor form triggers the plug-in
4.2Command Automation Interface (CAI) – libcaieventcmd/caiventcmd.dll :Primarily used by Requestor Console ,SRMS,TMS etc. CAI subsystem provides a common infrastructure that can be shared across applications for integration. It is a filter API plug-in
DVF Plug-ins ( These are for data visualization to provide graphical representation of data)
1.Task Viewer – Provides a graphical representation of tasks, task groups and their sequencing
2.Change/Release Calendar – Provides a calendar representation of changes/releases within the Organization.This is very important for scheduling changes /releases. Similar to outlook calendar view
5.Approval mapping & Integration with approval server
in ITSM,there is tight integration with approval server.Applications like change management have this integration because critical changes done to the production infrastructure needs to be following the approval process of the enterprise so that sufficient "what-if" scenarios can be thought about & appropriate sign-offs can be obtained.
Approval Mappings for Change Management Application is done from Application Administration Console>Custom Configuration>Change Management>Approval> Approval Mappings
Approval Process Configuration is done from Application Administration console>Custom Configuration>Foundation>Advanced Options>Approval Process Configuration
The approval processes that are configured can be based on CI (Configuration Item) and IA (Impacted Area)
Approval Rules involved in these processes can be viewed/customized from the form AP:Administration console
6.Risk Management
Risk assessment within change management helps to achieve greater productivity by combining qualitative and quantitative criteria for assessing the risk level associated with a change.The computed risk value can be selected, based on answers to a series of predefined questions.Derived risk factors are based on the historical performance of different aspects of a change. For all configured derived risks, a cumulative performance rating is stored
7.Release Manifest The points below were consolidated so that it can benefit everyone who works on BMC Remedy ITSM.
1.Multi-tenancy
In the BMC Remedy ITSM applications, the multi-tenancy feature is available for Data segregation based on company. Access to data is controlled by a user’s access to a company.
(reading up a little bit about field 112 would be helpful as-well).
This feature is enabled from Application Administration Console>Custom Configuration>Foundation>Advanced Options>System Configuration Settings-System Settings
2.Restricted and Unrestricted access
This is related to multi-tenancy & for restricting data access of individuals to only companies that are relevant for them.Unrestricted users can access data for all companies based on there application permissions (Say a Global Support Manager).This is configured from People form’s Login/Access Tab.Check “Unrestricted Access” for granting such an access to a user.For restricting access to specific companies, add them into “Access Restrictions” Table
3.ITSM in a DSO environment
ITSM Installer now provides more support for DSO (7.5.xx onwards).Another good thing about the installer is that it is consolidated (ServiceDesk,Change Management & Asset Management) & runs on multiple platforms (InstallAnywhere based).Enable user defined prefix from SYS:System Settings.The 'Custom prefixes' are one of the most important aspects of a DSO enabled environment for ITSM.Update SHR:SchemaNames in the other server for appropriate application prefix (user defined prefix).Update field default for field ID 1 to match the prefix setup in above step.For additional information,refer ITSM-DSO-Enablement.doc
4.ITSM plug-ins
Another common query is regarding the plugins used by ITSM.Below is a list of few important ones
4.1ARDBC Plugin : Provides Overview console functionality, a view of work assigned across multiple applications. Query on the Vendor form triggers the plug-in
4.2Command Automation Interface (CAI) – libcaieventcmd/caiventcmd.dll :Primarily used by Requestor Console ,SRMS,TMS etc. CAI subsystem provides a common infrastructure that can be shared across applications for integration. It is a filter API plug-in
DVF Plug-ins ( These are for data visualization to provide graphical representation of data)
1.Task Viewer – Provides a graphical representation of tasks, task groups and their sequencing
2.Change/Release Calendar – Provides a calendar representation of changes/releases within the Organization.This is very important for scheduling changes /releases. Similar to outlook calendar view
5.Approval mapping & Integration with approval server
in ITSM,there is tight integration with approval server.Applications like change management have this integration because critical changes done to the production infrastructure needs to be following the approval process of the enterprise so that sufficient "what-if" scenarios can be thought about & appropriate sign-offs can be obtained.
Approval Mappings for Change Management Application is done from Application Administration Console>Custom Configuration>Change Management>Approval> Approval Mappings
Approval Process Configuration is done from Application Administration console>Custom Configuration>Foundation>Advanced Options>Approval Process Configuration
The approval processes that are configured can be based on CI (Configuration Item) and IA (Impacted Area)
Approval Rules involved in these processes can be viewed/customized from the form AP:Administration console
6.Risk Management
Risk assessment within change management helps to achieve greater productivity by combining qualitative and quantitative criteria for assessing the risk level associated with a change.The computed risk value can be selected, based on answers to a series of predefined questions.Derived risk factors are based on the historical performance of different aspects of a change. For all configured derived risks, a cumulative performance rating is stored
The Release manifest defines the content of the Release.The manifest can consist of Activities and/or Change Requests.Manifest is used to provide a consolidated view needed to drive completion of the Changes and the Activities required to Close the Release.
Milestones are used to provide grouping mechanism to identify key points within in the Release process.
8.ITSM Notifications
Notifications are very important from the application's perspective because they keep key people informed
You can customize an individual’s notification preferences. Notification preferences vary by module
User Level - General preferences - They are configured in Notifications tab in people form
Configurable from the Notification tab of Application Rules
Notifications are Message Tag/Event DrivenYou can customize your own notification messages from the SYS:Notification Messages form. The SYS:Notification Messages form contains the notification text for each event.
Notification Message Tag is used by the notification workflow to identify the specific message to be sent. Each notification event can be associated with several notification messages.
formed on what is going on.
9.Impact Analysis
Change Impact Management: Thre are ways of Automated, intelligent and accurate change impact assessment to pro-actively determine impact to Services and mitigate risk of implementing a Change Request .When touching a CI it is difficult to understand the impact of the change: Atrium Impact Simulator -Provides “what if” CI impact analysis for ITSM applications.Higher level of service assurance can be provided before planning or approving changes to the production environment.This will reduce possible change collisions-(using Collision Detection functionality)
10.Integration with external apps – Web service & interface forms
Integration with external apps can be esility done with Web service & interface forms
Web services allow third-party integration tools to create, modify and query requests
They are built on top of Application Interface forms which has the Ability to Create requests, specify templates and associations.We can query and modify relationships and work info entries etc associated with a request
e.g. for a webservice is RMS_ReleaseInterface_Create_WS
Subscribe to:
Posts (Atom)